Was this page helpful?
Caution
You're viewing documentation for a previous version. Switch to the latest stable version.
Global Secondary Indexes¶
The data model in ScyllaDB partitions data between cluster nodes using a partition key, which is defined in the database schema. This is an efficient way to look up rows because you can find the node hosting the row by hashing the partition key.
However, this also means that finding a row using a non-partition key requires a full table scan which is inefficient.
Global Secondary indexes (named “Secondary indexes” for the rest of this doc) are a mechanism in ScyllaDB which allows efficient searches on non-partition keys by creating an index. They are indexes created on columns other than the entire partition key, where each secondary index indexes one specific column. A secondary index can index a column used in the partition key in the case of a composite partition key.
Secondary indexes provide the following advantages:
Secondary Indexes are (mostly) transparent to your application. Queries have access to all the columns in the table, and you can add or remove indexes on the fly without changing the application.
We can use the value of the indexed column to find the corresponding index table row in the cluster so that reads are scalable.
Updates can be more efficient with secondary indexes than materialized views because only changes to the primary key and indexed column cause an update in the index view.
What’s more, the size of an index is proportional to the size of the indexed data. As data in ScyllaDB is distributed to multiple nodes, it’s impractical to store the whole index on a single node, as it limits the size of the index to the capacity of a single node, not the capacity of the whole cluster.
For this reason, secondary indexes in ScyllaDB are global rather than local. With global indexing, a materialized view is created for each index. This materialized view has the indexed column as a partition key and primary key (partition key and clustering keys) of the indexed row as clustering keys.
Secondary indexes created globally provide a further advantage: you can use the value of the indexed column to find the corresponding index table row in the cluster so reads are scalable. Note however, that with this approach, writes are slower than with local indexing because of the overhead required to keep the indexed view up to date.
How Secondary Index Queries Work¶
ScyllaDB breaks indexed queries into two parts:
a query on the index table to retrieve partition keys for the indexed table, and
a query to the indexed table using the retrieved partition keys.
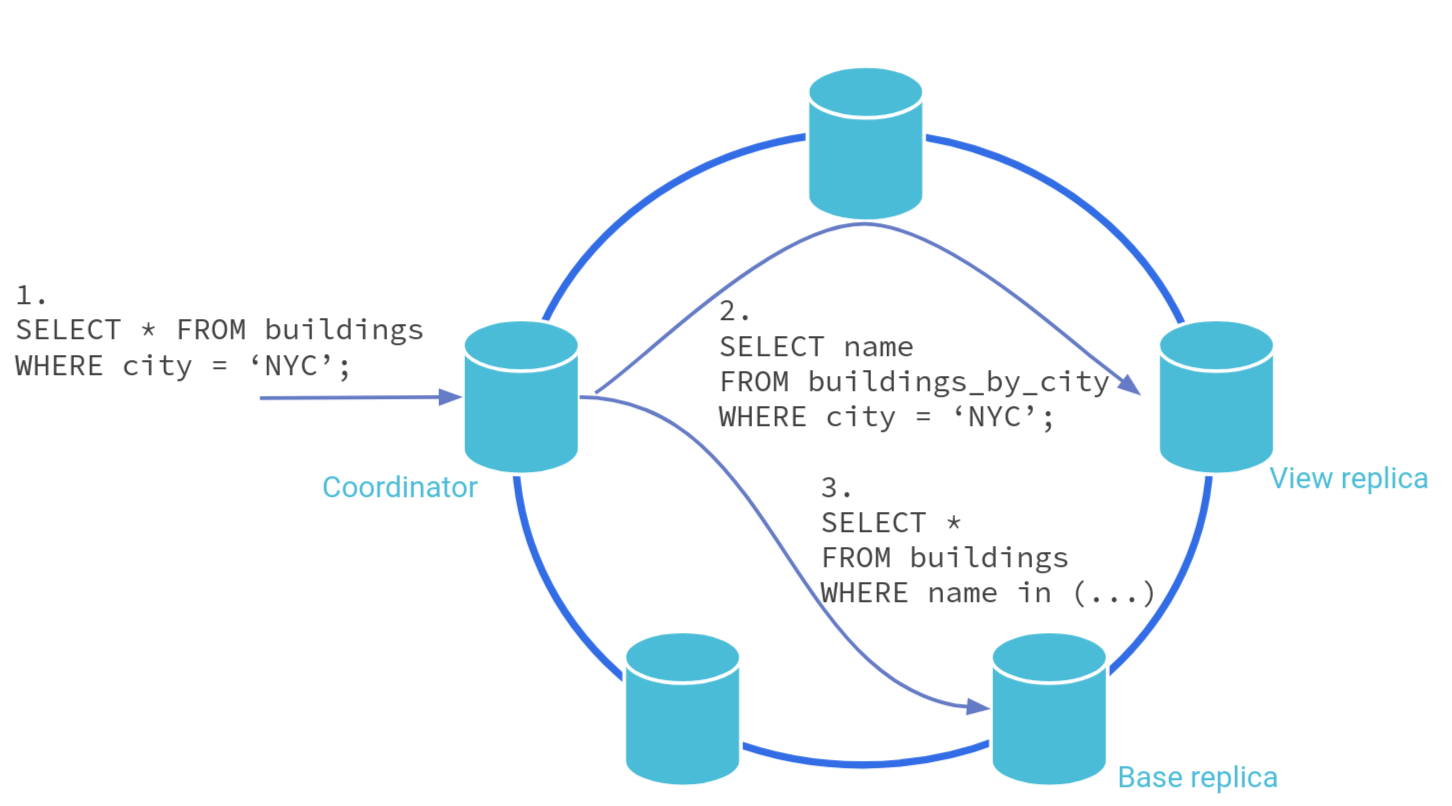
In the example above:
The query arrives to a coordinator
The node notices the query on an index column and issues a read to an index table, which has the index table row for the base table
This query will return a partition key for the base table that is used to retrieve contents of the base table.
Example¶
The following is an example and does not contain all of the options available. To see all of the options available, refer to the CQL Reference.
Given the following schema:
CREATE TABLE buildings (name text, city text, height int, PRIMARY KEY (name));
Let’s populate it with some test data:
INSERT INTO buildings(name,city,height) VALUES ('Burj Khalifa','Dubai',828);
INSERT INTO buildings(name,city,height) VALUES ('Shanghai Tower','Shanghai',632);
INSERT INTO buildings(name,city,height) VALUES ('Abraj Al-Bait Clock Tower','Mecca',601);
INSERT INTO buildings(name,city,height) VALUES ('Ping An Finance Centre','Shenzhen',599);
INSERT INTO buildings(name,city,height) VALUES ('Lotte World Tower','Seoul',554);
INSERT INTO buildings(name,city,height) VALUES ('One World Trade Center','New York City',541);
INSERT INTO buildings(name,city,height) VALUES ('Guangzhou CTF Finance Centre','Guangzhou',530);
INSERT INTO buildings(name,city,height) VALUES ('Tianjin CTF Finance Centre','Tianjin',530);
INSERT INTO buildings(name,city,height) VALUES ('China Zun','Beijing',528);
INSERT INTO buildings(name,city,height) VALUES ('Taipei 101','Taipei',508);
Note that if we try to query on a column (the part after the WHERE clause) in a ScyllaDB table that isn’t part of the primary key, we’ll see that this is not permitted. For example:
SELECT * FROM buildings WHERE city = 'Shenzhen';
will result in an error.
Secondary indexes are designed to allow efficient querying of non-partition key columns. We can create an index on city by with the following CQL statements:
CREATE INDEX buildings_by_city ON buildings (city);
We can now query the indexed columns as if they were partition keys:
SELECT * FROM buildings WHERE city = 'Shenzhen';
returns
name | city | height
-----------------------+----------+--------
Ping An Finance Centre | Shenzhen | 599
(1 rows)
Note that you can use the DESCRIBE command to see the whole schema for the buildings table, including created indexes and views:
cqlsh:mykeyspace> DESC buildings;
CREATE TABLE mykeyspace.buildings (
name text PRIMARY KEY,
city text,
height int
) WITH bloom_filter_fp_chance = 0.01
AND caching = {'keys': 'ALL', 'rows_per_partition': 'ALL'}
...;
CREATE INDEX buildings_by_city ON mykeyspace.buildings (city);
CREATE MATERIALIZED VIEW mykeyspace.buildings_by_city_index AS
SELECT city, idx_token, name
FROM mykeyspace.buildings
WHERE city IS NOT NULL
PRIMARY KEY (city, idx_token, name)
WITH CLUSTERING ORDER BY (idx_token ASC, name ASC)
AND bloom_filter_fp_chance = 0.01
AND caching = {'keys': 'ALL', 'rows_per_partition': 'ALL'}
...
Note the Secondary Index is implemented as MATERIALIZED VIEW.
More information¶
CQL Reference - CQL Reference for Secondary Indexes
The following courses are available from ScyllaDB University: