Was this page helpful?
Caution
You're viewing documentation for a previous version. Switch to the latest stable version.
Lightweight Transactions¶
Note
The LWT feature is not supported in keyspaces with tablets enabled.
There are cases when it is necessary to modify data based on its current state: that is, to perform an update that is executed only if a row does not exist or contains a certain value. LWTs provide this functionality by only allowing changes to data to occur if the condition provided evaluates as true. The conditional statements provide linearizable semantics thus allowing data to remain consistent.
A basic rule of thumb is that any statement with an IF clause is a conditional statement. A batch that has at least one conditional statement is a conditional batch. Conditional statements and conditional batches are executed atomically, as a Lightweight Transaction (LWT) For example:
UPDATE employees SET join_date = '2018-05-19' WHERE
firstname = 'John' AND lastname = 'Doe'
IF join_date != null;
The example above updates the employee John Doe’s start date if John Doe has a record in the employees table.
The IF clause¶
Creating a conditional statement with an IF clause can include a query of individual cells and or collection elements.
It can use IN clauses or comparison operators, such as <, >, >=, <=, ==, and !=.
The important part to keep in mind is that in order to initiate the transaction, the condition must evaluate to true and if there are several different elements in the conditional statement, each part must evaluate to true.
If any part evaluates to false the transaction does not complete.
The IF condition can be created from any of the following CQL components: IF EXISTS, IF NOT EXISTS, or one or more predicates on the existing row.
What row does IF clause apply to?¶
Conditional statements which evaluate or assign non-static columns must specify both the clustering key and the partition key. Such statements are said to apply to regular rows; statements which only restrict the partition key must use only static columns and are said to apply to the static row of the partition.
A regular row exists if at least one regular cell or the clustering key is assigned. For example, consider the following table:
CREATE TABLE t (
p INT,
c INT,
r INT,
s INT STATIC,
PRIMARY KEY(p, c));
It has a partition key p, a clustering key c, a regular
cell r and a static cell s.
To materialize a regular row, it’s sufficient to assign any of
c or r:
> INSERT INTO t (p, c, r) VALUES (1,1,NULL) IF NOT EXISTS;
+-------------+------+------+------+------+
| [applied] | p | c | s | r |
|-------------+------+------+------+------|
| True | null | null | null | null |
+-------------+------+------+------+------+
> INSERT INTO t (p, c, r) VALUES (1,1,NULL) IF NOT EXISTS;
+-------------+-----+-----+------+------+
| [applied] | p | c | s | r |
|-------------+-----+-----+------+------|
| False | 1 | 1 | null | null |
+-------------+-----+-----+------+------+
To materialize a static row, one must explicitly assign at least one static cell: otherwise the static row is not considered present:
> INSERT INTO t (p, s) VALUES (1,NULL) IF NOT EXISTS;
+-------------+-----+------+------+------+
| [applied] | p | c | s | r |
|-------------+-----+------+------+------|
| True | 1 | null | null | null |
+-------------+-----+------+------+------+
> INSERT INTO t (p, s) VALUES (1,NULL) IF NOT EXISTS;
+-------------+-----+------+------+------+
| [applied] | p | c | s | r |
|-------------+-----+------+------+------|
| True | 1 | null | null | null |
+-------------+-----+------+------+------+
It is OK to us a comparison with NULL in a condition.
But since NULL value and missing value in ScyllaDB are
indistinguishable, conditions which compare with NULL
will return the same result when applied to both
missing rows or existing rows with NULL cells:
> UPDATE t SET s=2 WHERE p=1 IF s = NULL;
+-------------+------+
| [applied] | s |
|-------------+------|
| True | null |
+-------------+------+
If a regular row is missing, but the static row cells are assigned, the static cells will be present in the row used to evaluate the condition of the “missing” regular row:
> UPDATE t SET r=2 WHERE p=1 AND c=2 IF s = 2;
+-------------+-----+
| [applied] | s |
|-------------+-----|
| True | 2 |
+-------------+-----+
ScyllaDB Paxos¶
The statements with an IF clause use a different write path, employing the Paxos consensus algorithm (see figure) to ensure linearizability of the execution history.
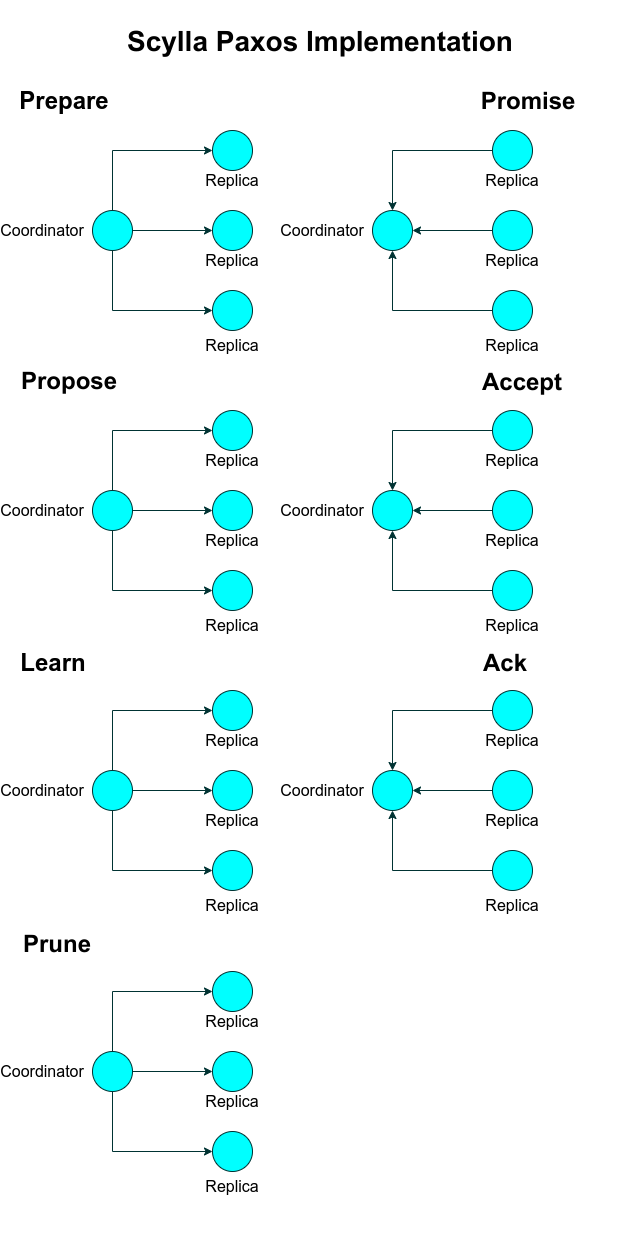
In Paxos, in order to persist a change a coordinator first must create a unique time-based identifier, called a ballot, and send it to replicas. Upon receiving a ballot, replicas respond with a promise to accept a change associated with it.
A replica refuses to promise a ballot if it has already promised a newer one – this locks out concurrent modification attempts and allows the coordinator to proceed with reading and updating a row without interference. The state of the protocol is persisted in system.paxos table, which is local to each replica.
Unlike Cassandra, ScyllaDB piggy-backs the old version of the row on response to “Prepare” request, so reading a row doesn’t require a separate message exchange.
Once the coordinator gets a majority of promises from replicas,
it evaluates the IF conditions, and if the result is true,
sends an updated mutation to replicas.
Replicas store the new row in system.paxos and acknowledge
accepting it.
Having a majority of replicas accept the row satisfies the “quorum intersection” rule: as long as at least a majority of nodes are up, each conceivable new quorum contains at least one node which accepted the previous row and is thus aware of the change.
After the coordinator has received the majority of accepts, Paxos protocol round is complete, and it is safe to update the base table with the new row. This is done in “Learn” round.
If the base table update is successful, the coordinator responds to the client. It’s also safe to prune the state of the protocol from system.paxos.
The size of the quorum impacts how many acknowledgements the
coordinator must get before proceeding to the next round or
responding to the client. For Prepare and Accept, it is configured
with SERIAL CONSISTENCY setting. For Learn, ScyllaDB’s eventual
CONSISTENCY is used. Pruning is done in the background.
Key differences between ScyllaDB and Cassandra Paxos implementations are in collapsing prepare and read actions into a single round, and also introducing an extra asynchronous “prune” round, which keeps system.paxos table small and thus reduces write amplification when it’s compacted.
Note
TTL on records in system.paxos table is set with the paxos_grace_seconds value.
If this value is not set, the value from gc_grace_seconds is used.
The default for gc_grace_seconds and paxos_grace_seconds are both the same (10 days).
You can have two different settings for paxos_grace_seconds and gc_grace_seconds.
You can change the paxos_grace_seconds value by altering the system.paxos table.
Batch statements¶
BATCH statements may contain one or more conditional statements and as such, these batches are called conditional batches.
The entire conditional batch has an isolated view of the database and is executed using all-or-nothing principle. In many ways, conditional batches are similar to ACID transactions in relational databases, with the exception that a batch is executed only if all conditions in all statements are true, if not it does nothing.
Reading with Paxos¶
For queries against a single partition, it’s possible to use Paxos
for reading. Paxos reads are useful if it’s necessary to retrieve
the most up to date version of a row: a simple QUORUM read may not
see a value that is currently being updated by a conditional
write. In order to ensure a read is serial, set CONSISTENCY to
SERIAL in cqlsh or prepared statement properties.
SELECT * FROM employees WHERE firstname = 'John' AND lastname = 'Doe'
CQL examples with lightweight transactions¶
Add values to a table with LWT¶
Suppose you have a company which advertises movies playing in the cinema. The application allows customers to search for a movie, and to buy a ticket. You can use lightweight transactions for any of the following activities:
Change the existing movie’s offering by adding a new movie screening time (and not changing the other data for the movie)
Remove a movie which is no longer playing
Add a new movie to the New Releases page (as long as it isn’t already there)
Create a Keyspace
CREATE KEYSPACE movies WITH replication = {'class': 'NetworkTopologyStrategy', 'replication_factor' : 3};
Create a table
CREATE TABLE movies.nowshowing ( movie TEXT, director TEXT static, main_actor TEXT static, released DATE static, location TEXT, run_day TEXT, run_time TIME, theater TEXT, PRIMARY KEY (movie, location, run_day, run_time) );
Insert values into the table using LWT:
INSERT INTO movies.nowshowing (movie, director, main_actor, released) VALUES ('Sonic the Hedgehog', 'Jeff Fowler', 'Ben Schwartz', '2020-14-02') IF NOT EXISTS;
INSERT INTO movies.nowshowing (movie, director, main_actor, released) VALUES ('Invisible Man', 'Leigh Whannell', 'Elisabeth Moss', '2020-28-02') IF NOT EXISTS;
Show the current table
SELECT * FROM movies.nowshowing; movie | location | run_day | run_time | director | main_actor | released | theater --------------------+----------+---------+----------+----------------+----------------+------------+--------- Sonic the Hedgehog | null | null | null | Jeff Fowler | Ben Schwartz | 2021-02-02 | null Invisible Man | null | null | null | Leigh Whannell | Elisabeth Moss | 2022-04-06 | null (2 rows)
Add more information to the table
INSERT INTO movies.nowshowing (movie, location, theater, run_day, run_time) VALUES ('Sonic the Hedgehog', 'Times Square', 'AMC Empire 25', 'Saturday', '21:00:00') IF NOT EXISTS;
INSERT INTO movies.nowshowing (movie, location, theater, run_day, run_time) VALUES ('Sonic the Hedgehog', 'Penn Station', 'AMC 34th Street 14', 'Sunday', '14:00:00') IF NOT EXISTS;
INSERT INTO movies.nowshowing (movie, location, theater, run_day, run_time) VALUES ('Sonic the Hedgehog', 'Times Square', 'AMC Empire 25', 'Saturday', '14:00:00') IF NOT EXISTS;
INSERT INTO movies.nowshowing (movie, location, theater, run_day, run_time) VALUES ('Sonic the Hedgehog', 'Penn Station', 'AMC 34th Street 14', 'Sunday', '21:00:00') IF NOT EXISTS;
INSERT INTO movies.nowshowing (movie, location, theater, run_day, run_time) VALUES ('Invisible Man', 'Times Square', 'AMC Empire 25', 'Friday', '21:00:00') IF NOT EXISTS;
INSERT INTO movies.nowshowing (movie, location, theater, run_day, run_time) VALUES ('Invisible Man', 'Penn Station', 'AMC 34th Street 14', 'Sunday', '22:00:00') IF NOT EXISTS;
INSERT INTO movies.nowshowing (movie, location, theater, run_day, run_time) VALUES ('Invisible Man', 'Times Square', 'AMC Empire 25', 'Saturday', '22:00:00') IF NOT EXISTS;
INSERT INTO movies.nowshowing (movie, location, theater, run_day, run_time) VALUES ('Invisible Man', 'Penn Station', 'AMC 34th Street 14', 'Sunday', '18:00:00') IF NOT EXISTS;
Show the current table
SELECT * FROM movies.nowshowing; movie | location | run_day | run_time | director | main_actor | released | theater --------------------+--------------+----------+--------------------+----------------+----------------+------------+-------------------- Sonic the Hedgehog | Penn Station | Sunday | 14:00:00.000000000 | Jeff Fowler | Ben Schwartz | 2021-02-02 | AMC 34th Street 14 Sonic the Hedgehog | Penn Station | Sunday | 21:00:00.000000000 | Jeff Fowler | Ben Schwartz | 2021-02-02 | AMC 34th Street 14 Sonic the Hedgehog | Times Square | Saturday | 14:00:00.000000000 | Jeff Fowler | Ben Schwartz | 2021-02-02 | AMC Empire 25 Sonic the Hedgehog | Times Square | Saturday | 21:00:00.000000000 | Jeff Fowler | Ben Schwartz | 2021-02-02 | AMC Empire 25 Invisible Man | Penn Station | Sunday | 18:00:00.000000000 | Leigh Whannell | Elisabeth Moss | 2022-04-06 | AMC 34th Street 14 Invisible Man | Penn Station | Sunday | 22:00:00.000000000 | Leigh Whannell | Elisabeth Moss | 2022-04-06 | AMC 34th Street 14 Invisible Man | Times Square | Friday | 21:00:00.000000000 | Leigh Whannell | Elisabeth Moss | 2022-04-06 | AMC Empire 25 Invisible Man | Times Square | Saturday | 22:00:00.000000000 | Leigh Whannell | Elisabeth Moss | 2022-04-06 | AMC Empire 25 (8 rows)
Update a table using a LWT¶
In this example the Times Square AMC theater needs to change the theater name from AMC Empire 25 to AMC Empire. It can be done using a conditional UPDATE, as shown here:
Update the table:
UPDATE movies.nowshowing SET theater = 'AMC Empire' WHERE location = 'Times Square' AND run_day = 'Saturday' AND run_time ='14:00:00' AND Movie = 'Sonic the Hedgehog' IF EXISTS; [applied] | movie | location | run_day | run_time | director | main_actor | released | theater -----------+--------------------+--------------+----------+--------------------+-------------+--------------+------------+--------------- True | Sonic the Hedgehog | Times Square | Saturday | 14:00:00.000000000 | Jeff Fowler | Ben Schwartz | 2021-02-02 | AMC Empire 25
Show the current table, note the third line where the theater is now AMC Empire.
SELECT * FROM movies.nowshowing; movie | location | run_day | run_time | director | main_actor | released | theater --------------------+--------------+----------+--------------------+----------------+----------------+------------+-------------------- Sonic the Hedgehog | Penn Station | Sunday | 14:00:00.000000000 | Jeff Fowler | Ben Schwartz | 2021-02-02 | AMC 34th Street 14 Sonic the Hedgehog | Penn Station | Sunday | 21:00:00.000000000 | Jeff Fowler | Ben Schwartz | 2021-02-02 | AMC 34th Street 14 Sonic the Hedgehog | Times Square | Saturday | 14:00:00.000000000 | Jeff Fowler | Ben Schwartz | 2021-02-02 | AMC Empire Sonic the Hedgehog | Times Square | Saturday | 21:00:00.000000000 | Jeff Fowler | Ben Schwartz | 2021-02-02 | AMC Empire 25 Invisible Man | Penn Station | Sunday | 18:00:00.000000000 | Leigh Whannell | Elisabeth Moss | 2022-04-06 | AMC 34th Street 14 Invisible Man | Penn Station | Sunday | 22:00:00.000000000 | Leigh Whannell | Elisabeth Moss | 2022-04-06 | AMC 34th Street 14 Invisible Man | Times Square | Friday | 21:00:00.000000000 | Leigh Whannell | Elisabeth Moss | 2022-04-06 | AMC Empire 25 Invisible Man | Times Square | Saturday | 22:00:00.000000000 | Leigh Whannell | Elisabeth Moss | 2022-04-06 | AMC Empire 25 (8 rows)
Update a table using a conditional batch¶
Suppose you want to update the run time of a movie at a certain location. As the run time is part of the primary key, you cannot modify it. However, you can remove and re-insert the record.
Run a batch job which removes and inserts a record:
BEGIN BATCH DELETE FROM movies.nowshowing WHERE movie = 'Sonic the Hedgehog' AND location = 'Times Square' AND run_day = 'Saturday' AND run_time = '21:00:00' IF EXISTS INSERT INTO movies.nowshowing (movie, location, theater, run_day, run_time) VALUES ('Sonic the Hedgehog', 'Times Square', 'AMC Empire 25', 'Saturday', '23:00:00') APPLY BATCH;
Show the current table
SELECT * FROM movies.nowshowing;
Delete a partition using a conditional batch¶
The movie, “Invisible Man” is no longer being played so the theater wants to delete it. This involves creating a batch job which will:
Mark the batch as conditional to make it atomic
Delete the entire partition
Run the following:
BEGIN BATCH UPDATE movies.nowshowing SET released = NULL WHERE movie = 'Invisible Man' IF EXISTS DELETE FROM movies.nowshowing WHERE movie = 'Invisible Man' APPLY BATCH;
How is IF different from WHERE?¶
One may think that IF clause should be used in place of WHERE - and this is true to a large extent, both accept expressions and are applied to the searched row.
Unlike the WHERE clause, IF conditions never use a secondary index; as the rows are fetched before a condition is evaluated.
Keep in mind that the IF condition applies only to a fully qualified row, meaning you must specify the partition key and in many cases the clustering key as well.
In the WHERE clause you would use DELETE or UPDATE or in SET. When using UPDATE and INSERT with WHERE you would also need the VALUES clause.
If your data selection fetches multiple rows, your IF condition cannot be ambiguous, meaning it can not evaluate to TRUE for one row and to FALSE for another.
This includes statements which restrict only the partition key, and not the clustering key, or the partition key and multiple
clustering keys (pk = ? and ck IN (?, ?, ?). In these instances, only the conditions on static cells are accepted.
Working with conditional statement result set¶
A conditional statement always returns a result set. The result
set’s first column [applied] is special: it indicates whether
the statement was applied or not. Following the [applied]
column are the primary key columns
and then the columns used in the conditional expression. The result set
contains previous (old) values for these columns. If condition is
IF EXISTS or IF NOT EXISTS all columns of the column
family become part of the result set.
If the statement inserts a new row so previous values did not exist, the result will contain
NULLs.
A batch statement may contain multiple conditional statements. Each conditional statement of a batch yields a row of the result set, and these rows are returned in statement order. Non-conditional statements may be present in a conditional batch, but do not contribute to the result set. The set of columns of conditional batch result set is a set union of all columns used in conditional expressions of all conditional statements of the batch.
BEGIN BATCH
UPDATE movies.nowshowing SET main_actor = 'Aldis Hodge' WHERE movie = 'Invisible Man' IF main_actor = 'Elisabeth Moss'
UPDATE movies.nowshowing SET director = 'Mr Saw ' WHERE movie = 'Invisible Man' IF director = 'Leigh Whannell'
APPLY BATCH;
[applied] | movie | location | run_day | run_time | director | main_actor
-----------+---------------+----------+---------+----------+----------------+----------------
True | Invisible Man | null | null | null | Leigh Whannell | Elisabeth Moss
True | Invisible Man | null | null | null | Leigh Whannell | Elisabeth Moss
Error handling¶
Error executing a conditional statement (LWT) does not necessarily mean it failed. In addition to standard causes for failure such as client-side timeouts, server overload, memory allocation error, Paxos has its own scenarios leading to uncertainty:
An update started by one node is allowed to be overtaken and completed by another node.
The coordinator may fail or timeout after a write has succeeded at the majority of the participants and thus has de-facto committed.
To know for sure, a client must read the value back or retry the operation until it succeeds. Retrying should be done only if the failure is transient. It would be useless to retry in case of, e.g., a syntax error. Let’s consider some transient errors in more detail.
Error |
Description |
|---|---|
Unavailable exception |
Indicates that the coordinator is unable to contact the number of
replicas required by the statement consistency level.
This can happen because one or more nodes are down.
Alternatively, the ring simply may not have enough replicas
to satisfy the keyspace replication factor.
The coordinator performs availability checks independently for Paxos
COMMIT and LEARN steps to satisfy |
Write timeout |
A write timeout can happen at any step of Paxos. If it happens after the majority of the nodes has received the write, the write will be committed despite the failure. |
Read timeout |
Has the same meaning as Write timeout, but is returned for SELECTs. Internally, conditional updates may perform reads, but timeouts during these are still returned as write timeouts. |
Limitations¶
The following limitations apply:
You cannot use conditional batches to modify multiple partitions
You cannot use LWT with tables which use counters
When using user-supplied timestamps, you must make sure that the timestamp is assigned by the transaction coordinator. If not, it will not be possible to guarantee consistency.
It is not recommended to use conditional (LWT) and non-conditional statements with the same data set as it is not possible to ensure that conditional statements are consistent in this case. In short, all LWT data sets should not use write operations that are not LWT in structure.
Other limitations are more minor:
While a non-LWT batch can be UNLOGGED, a conditional batch cannot;
IF conditions must be a perfect conjunct (… AND … AND …);
Conditional batches are always logged in system.paxos table, so UNLOGGED keyword is silently ignored for them.
Additional Information¶
How does ScyllaDB LWT Differ from Apache Cassandra ? - How does ScyllaDB’s implementation of lightweight transactions differ from Apache Cassandra?
How to Change gc_grace_seconds for a Table - How to change the
gc_grace_secondsparameter for a table